数仓工具的使用
数仓工具的使用
你我皆温柔数仓工具的使用
数仓工具DataX的使用
1. 概述与架构
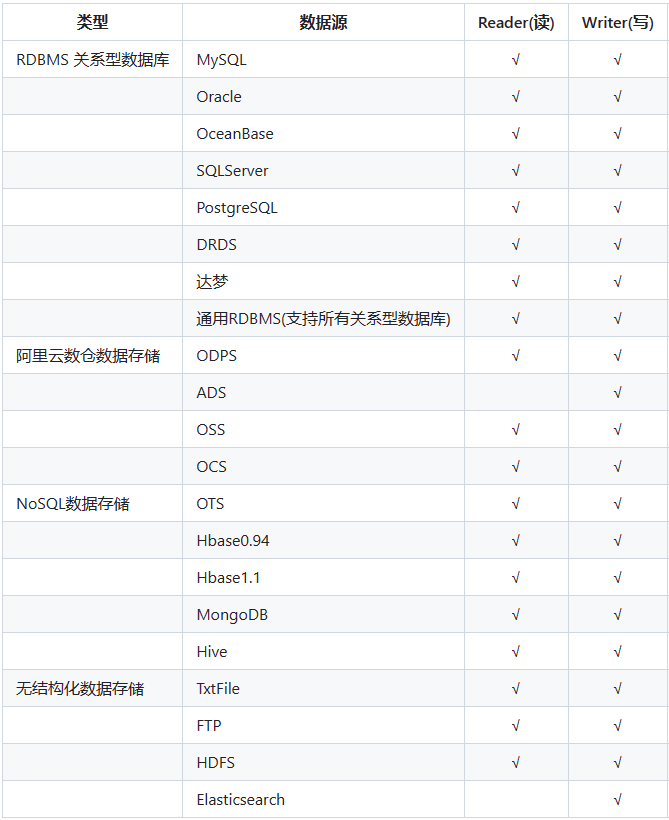
阿里推出的==异构数据源离线同步 工具==
Framework+plugin

- Framework:数据传输的管道,处理缓冲、流量控制、并发、数据转换
- Reader:数据采集模块,采集数据源数据
- Writer:数据写入模块,将数据写入下沉地(sink)HDFS
数据源

2. 写入hdfs
MySQL创建表
1
2
3
4
5
6create database if not exists test character set utf8;
use test;
create table student(id int,name varchar(20),age int,createtime timestamp );
insert into `student` (`id`, `name`, `age`, `createtime`) values('1','zhangsan','18','2021-05-10 18:10:00');
insert into `student` (`id`, `name`, `age`, `createtime`) values('2','lisi','28','2021-05-10 19:10:00');
insert into `student` (`id`, `name`, `age`, `createtime`) values('3','wangwu','38','2021-05-10 20:10:00');查看配置模板文件
1
2cd /export/server/datax
python ./bin/datax.py -r mysqlreader -w hdfswrite编写配置文件
1
2
3
4
5
6cd /export/server/datax/
vim /job/mysql2hdfs.json
根据官方文档配置
https://github.com/alibaba/DataX/blob/master/README.mdmysql数据写入hdfs
启动hdfs
启动datax执行json脚本
1
2cd /export/server/datax
python bin/datax/py job/mysql2hdfs.json进入HDFS页面,查看是否写入成功
3. 写入hive
创建配置文件
1
2cd /export/server/datax/
vim /job/mysql2hive.json创建Hive表
1
2
3
4
5
6
7
8
9create database IF NOT EXISTS test;
use test;
create table student(
id int,
name varchar(20),
age int,
createtime timestamp
)
row format delimited fields terminated by "\t" STORED AS TEXTFILE;使用datax使用JSON脚本
1
2cd /export/server/datax
python bin/datax.py job/mysql2hive.json进入HDFS页面,查看是否写入成功
4. DataX-Web的使用
1 | 进入datax目录 |
创建项目
配置数据源
配置目的地
创建任务模板(任务管理菜单)
在hive创建目标表
1
2
3
4
5
6
7
8
9
10create database IF NOT EXISTS test;
use test;
create table student2(
id int,
name varchar(20),
age int,
createtime timestamp
)
row format delimited fields terminated by ","
STORED AS TEXTFILE;构建json任务\json脚本
- 配置reader
- 配置writer
- 构建json脚本
- 选择执行任务模板
执行任务
查看日志
查看结果
DataX实现数据迁移
1. 建模设计
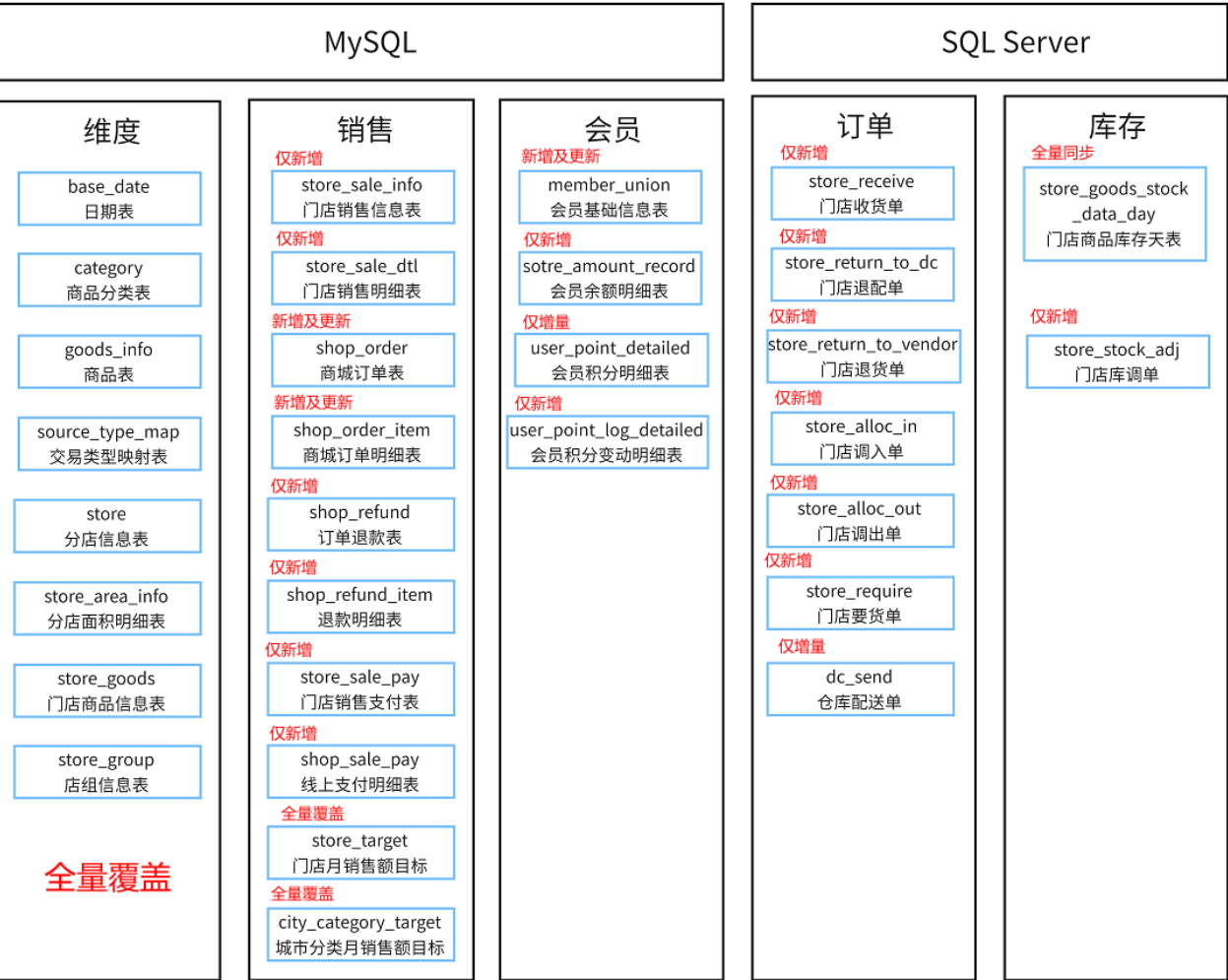
数据同步方式
- 全量覆盖
- 仅新增
- 新增或更新
- 全量同步
内部表还是外部表
- 根据是否对数据有完全的控制权
- 内部表对表数据有完全的控制权,删除数据时不仅可以删除元数据还可以删除实际数据
- 外部表仅支持删除元数据,不能删除实际数据
- 元数据存储在MySQL中,实际数据存储在HDFS中
分区表还是分桶表
- 分区表,将数据拆分成一个一个文件夹进行存储
- 分桶表将数据拆分成一个个数据文件进行存储,主要用来处理多表join、抽样
存储方式和压缩方式
- 存储方式
- 行式存储:textfile
- 列式存储:ORC、PARQUIT
- 压缩方式
- SNAPPY
- GZIP
- ZLIB
- 存储方式
表字段选择
- 根据用户需求确定
缓慢渐变维
1
2
3
4
5
6
7
8
9
10
11
12
13
14SCD1:不维护历史变更行为, 直接对过去数据进行覆盖即可
此种操作 仅适用于错误数据的处理
SCD2: 维护历史变化行为, 每天同步全量的数据, 不管是否有变化, 均全量维护到一个新的分区中
SCD3:维护历史变更行为,处理方式在表中新增两个新的字段,一个是起始时间,一个是结束时间,当数据发生变更后,将之前的数据设置为过期,将新的变更后完整的数据添加到表中,重新记录其起始和结束时间,将这种方案称为拉链表
好处:可以维护更多的历史版本的数据, 处理起来也是比较简单的 (利于维护)
弊端:造成数据冗余存储 大量占用磁盘空间
SCD4:维度历史变化,处理方式,当表中有字段发生变更后,新增一列,将变更后的数据存储到这一列中即可
好处:减少数据冗余存储
弊端:只能维护少量的历史版本, 而且维护不方便, 效率比较低
2. 构建原始业务表及导入数据
表类型:内部表+ORC+ZLIB+分区表
表字段
基于DataX-Web实现数据导入(全量覆盖)
- 新建数仓项目
- 创建任务模板:每天凌晨00:20:00执行一次,失败重新执行2次
- 添加数据源
- MySQL数据源
- Hive目标库
- 构建任务
- reader
- writer
- 字段映射
- 构建JSON文件-选择任务模板
- 将writeMode属性修改为 $ truncate$
- 执行任务
- 查看任务执行日志
- Hive中验证是否导入成功
基于DataX-Web实现数据导入(仅新增)
新建数仓项目
创建任务模板:每天凌晨00:20:00执行一次,失败重新执行2次
首次导入为全量覆盖,新增导入前一天的数据
全量覆盖等同 ==$ 基于DataX-Web实现数据导入(全量覆盖)$==
需要先将全部数据导入临时表
将临时表的数据进行分区处理,导入目标分区表
1
2
3
4
5insert into[overwrite] table ods.ods_sale_shop_refund_i partition (dt)
select
*,date(create_time) dt
-- date_format(create_time,'yyyy-MM-dd') as dt
from ods.ods_sale_shop_refund_i_temp;分区后,删除临时表
1
drop table ods.ods_sale_shop_refund_i_temp;
增量模式(T+1)
处理前一天的数据(在DataX的Reader中的where条件中添加如下语句)
1
2
3
4create_time between concat(date_sub(current_date,INTERVAL 1 DAY),' 00:00:00') and concat(date_sub(current_date,INTERVAL 1 DAY),' 23:59:59')
或者:
date_format(create_time,'%Y-%m-%d') = DATE_FORMAT(date_sub(NOW(),INTERVAL 1 DAY),'%Y-%m-%d')==将append修改为truncate==
==在任务列表里面编辑辅助参数(选择Hive分区)==
==在json配置文件中添加后执行sql:postSql属性中添加修复分区的sql==
1
2
3
4
5# 方式一: HIVE自动修复分区 (比较适合于有多个分区的情况)(推荐,可以在任务执行完成后自动执行)
MSCK REPAIR TABLE ods.ods_sale_shop_refund_i;
# 方式二:手动在hive中添加一个分区(不推荐)
alter table ods.ods_sale_shop_refund_i add partition (dt='2023-01-05')
执行任务
查看执行日志
hive中查看结果
HDFS中查看结果
新增及更新导入
- 首次导入同全量导入
- 增量导入,修改where条件==导入昨天一天新增的和更新的==
全量同步(相当于历史数据快照的功能)
- 创建一个新的分区
- 将所有的数据导入新的分区
- 仅保留近3个月的数据