数仓核心优化
数仓核心优化
你我皆温柔数仓核心优化
1. 数据采样
1.1. 分桶表(hash算法)
- 作用
- 数据采样
- 测试SQL是否可以正常运行
- 校验数据可行性
- 统计分析(相对性指标:比率)
- 提升join的查询效率
- 减少join次数
- 数据采样
1.2. 采样函数
- tablesample(bucket x out of y [on column])
- X 表示从第几个桶开始
- y 表示抽样比例
- column 表示抽样字段
2. join优化
1. 可能出现的问题
- 数据倾斜
- 所有的数据都在同一个reduce运算,reduce压力过大
2. 解决方案
2.1 map join (大表+小表)
- 将小表放一份到每个mapTask的内存中
- 设置参数
- set hive.auto.convert.join = True (开启map Join)
- set hive.euto.coonvert.join.noconditionaltask.size = 29321937838 (设置小表的最大阈值)
- 缺点
- 比较消耗内存
- 要求join中必须有小表,否则无法放入内存中
2.2 bucket map join (中型表 + 大表)
- 先过滤中型表后join
- 条件
- 两个表必须是分桶表
- 开启hive配置参数
- 分桶字段必须时join字段
- 大表的桶数必须是中型表桶数的整数倍
- 在map join的基础上(是几倍就分几桶)
2.3 SMB join(大表 + 大表)
- 使用条件
- 两个表都必须是分桶表
- 分桶数量是一致的
- 分桶列必须是join列,同时必须按分桶列进行排序
- 开启参数配置
- 建立在bucket map join的基础上
1 | 事实表 + 低基数维度表 join :map join 优化 |
3. Hive索引
3.1 原始索引
- 3.x版本被舍弃
- 不会自动更新索引,维护索引比较困难
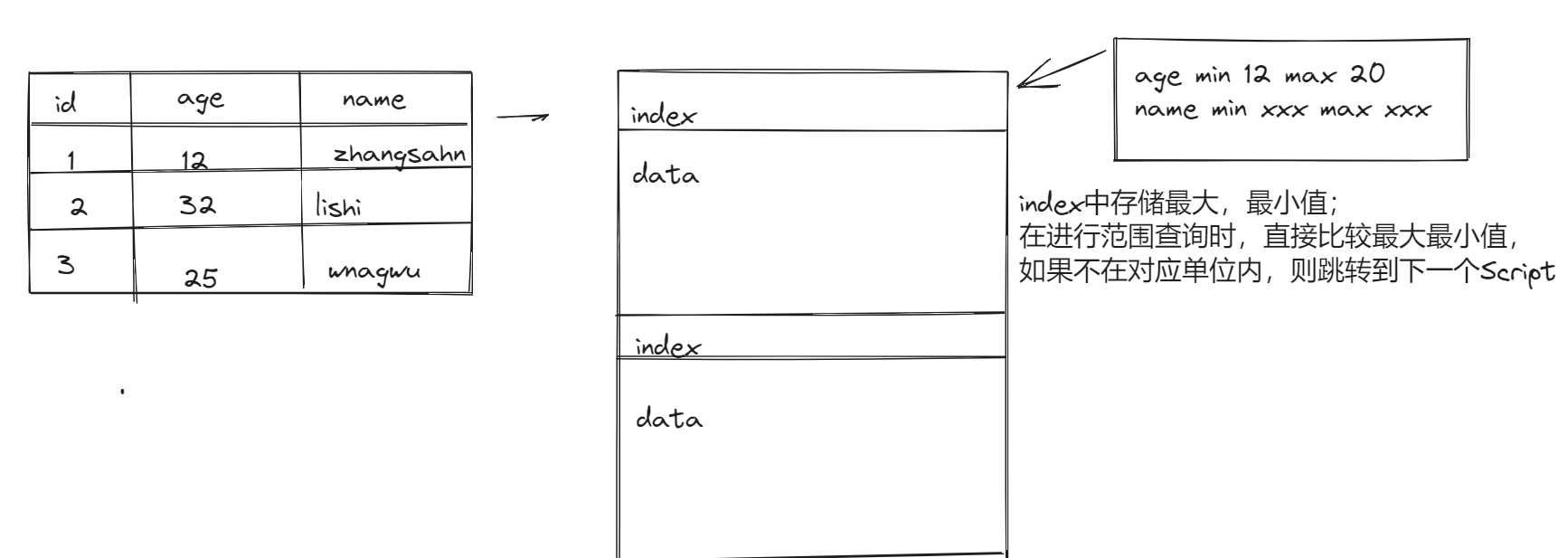
3.2 Row group index 索引
- 适用于 ==数值类型,范围查询==
- 必须是ORC存储格式
- 创建索引时,开启索引支持 $ ‘orc.create.index’=’true’$
- 插入数据时,必须保证按需求索引列顺序插入数据
- 原理

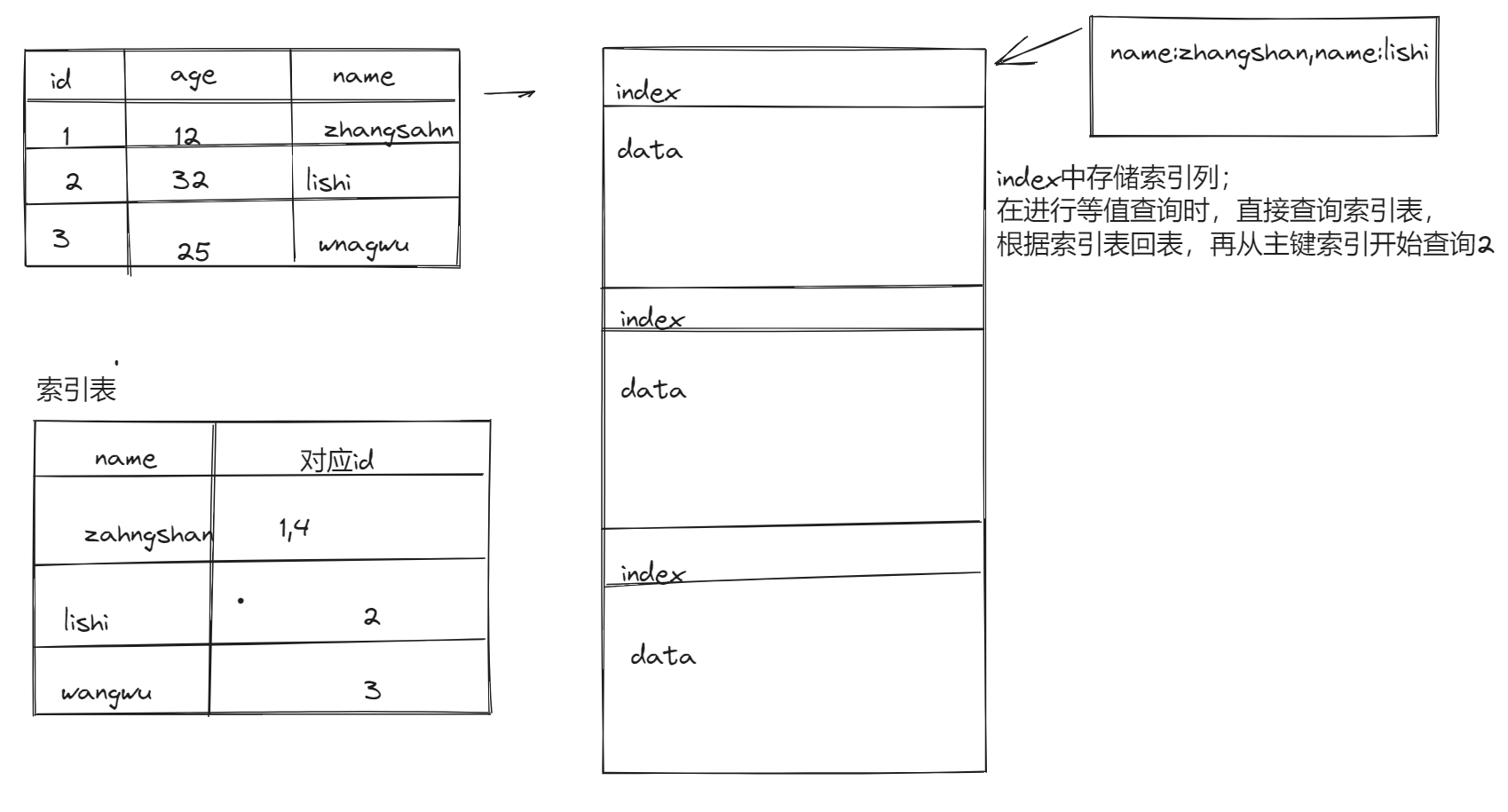
3.3 Bloom Filter index 索引
- 仅适用于等值过滤查询
- 必须是ORC存储格式
- 在建表的时候,设置索引列 $ ‘orc.bloom.filter.columns’ = ‘pcid,字段1,字段2, ….’$
- 原理
4. 数据倾斜
4.1 join数据倾斜
- 解决方案一
- map join
- bucket map join
- SMB join
- 解决方案二
- 将导致数据倾斜的Key及其对应的value单独放在一个MR中处理
- 运行期处理
- 在执行MR时,动态统计每个key出现的重复次数,到达一定阈值后,自动将其剔除交给一个单独的MR处理,所有MR处理完后,进行union all 合并
- 开启HIVE参数配置
- 编译期处理
- 在创建表时,猜测可能会导致数据倾斜的字段,提前配置好,MR在执行时遇到设置好的key,将其key 和 value 单独放到一个MR中进行处理,最后进行union all合并
- 开启hive参数配置
- union all (会运行MR,如何避免)
- 让每个MR运行完成后,直接将结果放入到目的地(即HDFS中指定目录)
- 开启hive参数配置
- 运行期处理
- 将导致数据倾斜的Key及其对应的value单独放在一个MR中处理
4.2 group by数据倾斜
- combiner提前聚合
- map阶段先进行一次聚合
- 一定程度上解决数据倾斜
- 开启hive参数配置
- 负载均衡
- 提供两个MR
- 第一个MR :打散随机分发
- 第二个MR :相同key分发到一起
- 开启hive参数配置
- 不能出现多次 distinct,仅支持1次
- ==如何预判数据倾斜????==
- 程序一直没有结束,大部分的MRTask已经执行完了,有部分还在执行,则可能发生了数据倾斜
- 运行结束的到jobhistory的UI中查看job中,查看Elapswed Time,时间相差2到3倍,认为可能发生了倾斜
- 运行状态中,在ResourceManager中的ApplicationMaster中查看运行时间
- 程序一直没有结束,大部分的MRTask已经执行完了,有部分还在执行,则可能发生了数据倾斜



