Hadoop原理
Hadoop原理
你我皆温柔Hadoop原理
框架

- 广义:Hadoop生态圈
- 狭义:Hadoop开源框架
- hdfs:解决海量数据存储
- mapreduce:解决海量数据的计算
- yarn:解决资源任务调度
- 分布式:多台服务器完成不同的事情
- 集群:多台计算机完成相同的事情
HDFS组件
分布式存储的原理
副本机制
1
2
3
4# 默认3副本机制
1、源文件存储在第一个DataNode上
2、第一个副本存储再和源文件不同机柜的服务器上(机柜就近原则)
3、第二个副本存储在和第一副本同一机柜的不同服务器上心跳机制
1
2
3DataNode每3秒向NameNode汇报一次自己的情况
若连续10次没有汇报,则NameNode会认为该DataNode可能已经宕机
NameNode会每5分钟发送一次确认消息,连续两次没有收到回复,就认定该DataNode宕机负载均衡机制
1
负载均衡保证给各个节点的任务分配的均匀一点
管理数据资源
分块管理
- 默认把数据切分为128M一块,默认3副本
- 可以再hdfs-site.xml中修改默认配置
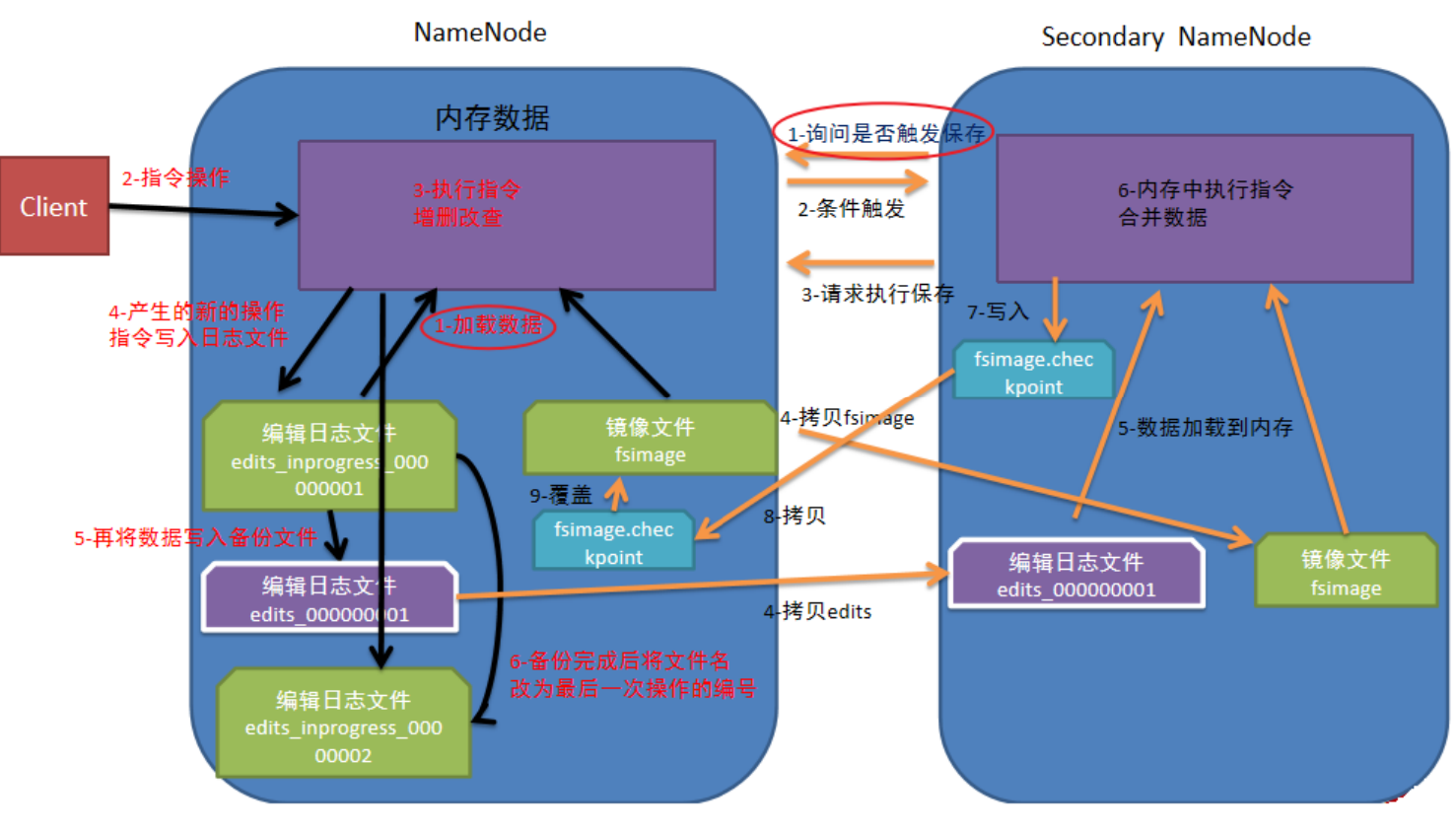
edits和fsimage
1
2
3
4
51. edits:存储的是操作日志、文件信息、块信息
2. fsimage:将多个edits合并成一个fsimage
3、存放路径:
NameNode: /export/data/hadoop/dfs/name/current/
DataNode: /export/data/hadoop/dfs/data/current/元数据文件
基于edits和fsimage对HDFS进行管理
1
2
3
4
5
61、每次对hdfs的操作都会记录再edits中
2、当一个edits到达一定的阈值后,会开启一个新的edits
3、当到达一定时间后,会合并成一个fsimage(1小时合并一次);如果提前到100W事务,将会提前合并(默认,可通过配置修改)
dfs.namenode.checkpoint.period,默认3600(秒)即1小时
dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
dfs.namenode.checkpoint.check.period,默认60(秒),来决定(60秒检查一次)
元数据存储原理
基础架构
- NameNode
- SecondaryNameNode
- DataNode
流程图

NameNode
1
管理元数据
DataNode
1
存储数据
SecondaryNameNode
1
备份NameNode
HDFS常见模式
- 安全模式:开启了安全模式,无法上传文件、创建目录
- 归档模式:将多个文件或目录归档到一个目录上
- 垃圾桶模式:开启后,通过shell删除的文件,可以保存在垃圾桶中,不会直接删除;但是通过页面删除的会直接永久删除
写数据操作流程
1
2
3
4
5
6
7
81、客户端向NameNode请求读取数据,NameNode验证客户端是否有写入权限
2、NameNode接收到请求后,告知客户端可以写入
3、客户端收到可以写入的消息后,将数据拆分成一个个128M的block信息,每个block拆分成一个个64k的数据包packet,并将他们加入传输队列中
4、客户端携带block信息,再次向NameNode发送请求,获取可以存储block的DataNode列表
5、NameNode就近查看有没有空闲的DataNode,将其写入DataNode列表中
6、客户端连接DataNode,开始发送数据包packet给DataNode,DataNode接收到数据包后给客户端一个ack应答报文,同时会将收到的数据包packet复制一份给DataNode2;DataNode2接受完数据后会把数据包packet复制一份给DataNode,DataNode3接受完数据包packet后,会发送一个ack应答报文给DataNode2,DataNode2收到ack应答报文后,会发送一份ack报文给DataNode
7、第一份数据包packet接收和复制完成后,开始接收下一个数据包packet,一直循环接收,直到所有block全部写入完成,文件则写入完成
8、最后NameNode和客户端确认全部写入完成,则文件写入完成读数据原理
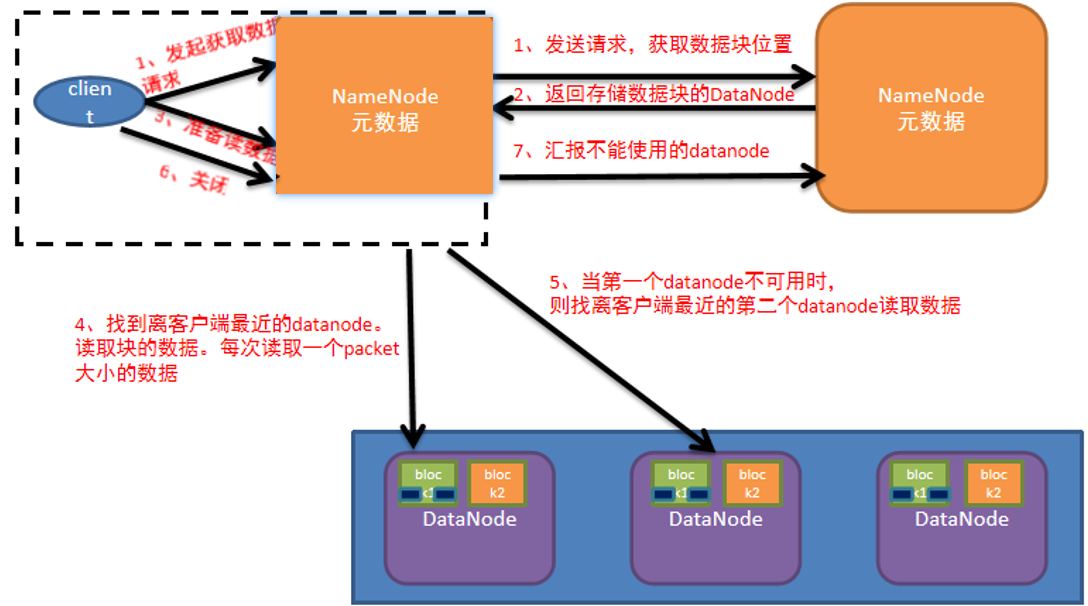
1
2
3
4
5
6
7
81、客户端向NameNode发送请求读取数据,NameNode验证客户端是否有读取权限、是否存有请求的文件、以及文件存储在哪个位置
2、验证通过后,告知客户端可以读取数据
3、客户端收到可以读取的应答后,需要和NameNode确认数据存储的位置信息等
4、NameNode查看较近的比较空闲的存有请求数据的DataNode,并将其加入DataNode列表中
5、客户端根据DataNode列表向DataNode请求读取数据
6、客户端开始读取数据按一块128M的block开始读取,放入缓冲区中
7、循环读取直到所有的block都读取完成
8、最后客户端把缓冲区中的数据通过流的形式写入到目标文件中

MapReduce组件
MapReduce的三个阶段
- Map阶段
- shuffle阶段
- reduce阶段
MapReduce的执行流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
181、Map阶段
1、将输入目录中的数据文件,切割成一个一个128M的block
2、按照一定的规则将数据解析成一个一个键值对,key是每一行文本的起始位置,value是文本内容
3、每个键值对都要调用map()方法,每次调用map()方法都会返回0个或多个键值对
4、按照一定的规则,对键值对进行分区
5、对每个分区的键值对进行排序(按照键进行排序,键相同的按照值排序)
6、对每个分区的数据进行局部的聚合处理
2、shuffle阶段
1、将MapTask的结果输出到100M的缓冲区中,保存的是key-value和分区信息等
2、当数据到达一定的阀值(80%)后,会将数据写入到磁盘中,在写入磁盘时会进行排序
3、将溢出的文件合并成一个临时文件,以确保只产生一个中间文件
4、ReduceTask启动fetcher线程,到已完成maptask的节点上复制一份数据到内存的缓冲区中,当达到一定的阀值后,会将缓冲区中的数据写入磁盘中
5、在ReduceTask远程复制同时,会在后台开启两个线程对内存到磁盘的数据文件进行合并
6、在进行合并的同时会对数据进行排序
3、Reduce阶段
1、Reduce会主动复制mapper任务输出的键值对
2、是把reduce复制到本地的数据全部进行合并,再对合并后的数据排序
3、对排序后的键值对调用reduce方法。键相同的调用一次reduce方法,最后把这些输出的键值对写入到HDFS文件中
Yarn组件
1.



