Hive调优
Hive调优
你我皆温柔Hive调优
参数配置
设置hive参数(三种方式)
配置hive文件
1
2
3a)用户自定义配置文件:$HIVE_CONF_DIR/hive-site.xml
b)默认配置文件:$HIVE_CONF_DIR/hive-default.xml.template
# 当用户自定义配置后,会覆盖默认配置。- 全局性,对所有hive进程
- hive的配置会覆盖Hadoop的配置,因为hive在客户端上运行
命令行参数配置
hive –service hiveserver2 –hiveconf 配置=参数
1
hive --service hiveserver2 --hiveconf hive.root.logger=DEBUG,console
仅在当前会话内有效
设置参数声明(推荐)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19-- 查看
set 配置;
-- 设定参数
set 配置=参数;
1、参数设置优先级
参数声明-->命令行参数--> 配置文件参数
2、参数设置范围
配置文件-->命令行参数--> 参数声明
-- 查看
set hive.exec.rowoffset;
-- 设置开启数据在hdfs偏移量显示
set hive.exec.rowoffset=true;
-- 查看
set mapreduce.job.reduces;
-- 设定reduce数量
set mapreduce.job.reduces = 3;
设定Fetch抓取策略
- 避免执行mapreduce
- 全表扫描
- 查询某一列
- 执行简单查询操作
- 执行limit
- 原理
- $ hive.fetch.task.conversion = more$ 可以保证在全表扫描、字段查找、简单查询、limit不走MR
- $ hive.fetch.task.conversion = minimal$ 保证执行全表扫描以及查询某几个列以及limit操作可以不走MR, 其他操作都会执
行MR - $ hive.fetch.task.conversion = none$ 全部都执行MR
- 避免执行mapreduce
设定本地模式
Hive可以通过本地模式在单台机器上处理所有的任务。而对于小数据集,执行时间可以明显被缩短
1
2
3
4
5
6-- 开启本地local mr , 默认为false
set hive.exec.mode.local.auto=true;
-- 设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=134217728;
-- 设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=4;
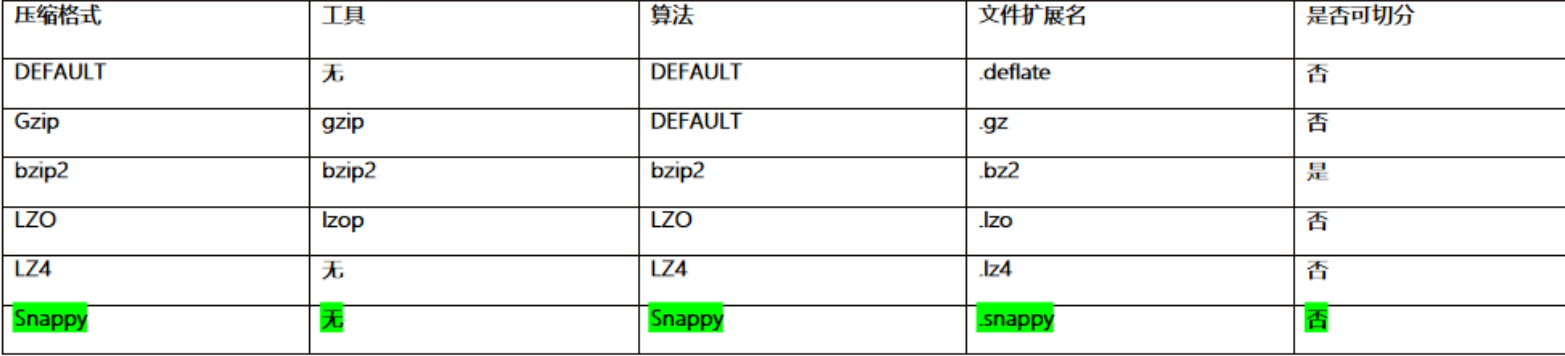
数据压缩格式
优势
1
2
3(1)便于集中处理;
(2)便于资料传输;
(3)便于阅读数据mapreduce支持的压缩格式

设定压缩方案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18-- 开启hive支持中间结果的压缩方案
set hive.exec.compress.intermediate = true
-- 开启hive支持最终结果压缩
set hive.exec.compress.output = true
--开启MR的mapper端压缩操作
set mapreduce.map.output.compress=true;
--设置mapper端压缩的方案
set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
-- 开启MR的reduce端的压缩方案
set mapreduce.output.fileoutputformat.compress=true;
-- 设置reduce端压缩的方案
set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
--设置reduce的压缩类型
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
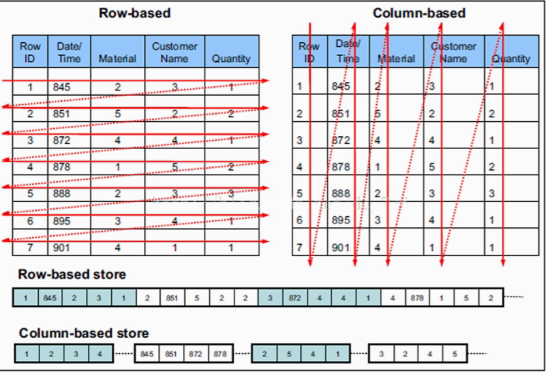
数据存储格式
行式存储
- TEXTFILE:存储方式为行存储
- 相关数据保存在一起,一行数据就是一条记录
- 缺点是,不能只取几列,不能跳过不必要的列
- TEXTFILE:存储方式为行存储
列式存储
- ORC:数据按行分块,每块按照列存储
- 可以只查询需要的列
- 压缩效率较高
- 缺点是insert和update很麻烦
- PARQUIT
- ORC:数据按行分块,每块按照列存储
建表语句
1
2
3
4
5
6
7
8
9
10
11
12
13create [external] table 表名(
字段名 字段类型,
字段名 字段类型,
...
)
[row format delimited
fields terminated by '指定分隔符']
[stored as textfile] -- 行式存储格式 18.1M
[stored as parquet] -- 列式存储格式 13.1M
[stored as orc]; -- 列式存储格式 2.8M
-- 导入数据
insert into table tb_col_parquet select * from taobao_log;