Hive基础(一)
Hive基础(一)
你我皆温柔Hive基础
什么是Hive
- 由fecebook开源,基于Hadoop的==离线数仓工具==
- 可用于结构化数据文件==映射==为一张表,提供类SQL查询
- 将SQL转换为MapReduce程序
用途
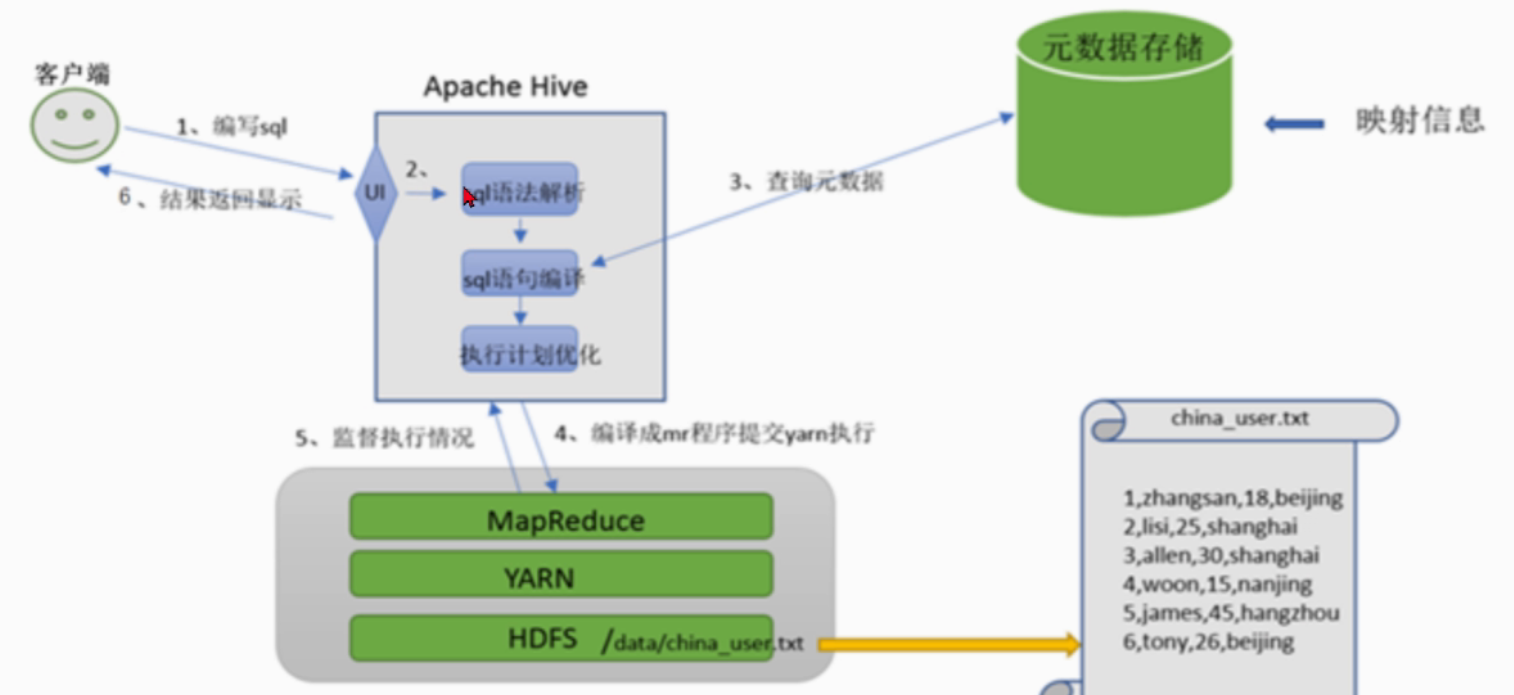
- 离线数仓(SQL–MapReduce)
- SQL–>MapReduce–>运算结果–>客户端
优缺点
- 优点
- 采用类SQL
- 避免直接写MapReduce
- 缺点
- 延迟高
- 对小数据处理没有优势,因为1
- 优点
数据库和数据仓库的区别
datagrip连接hive
1
数仓的分层架构
1
设计丐版Hive
需求
- 用户只需要写SQL
- 自动将SQL转化为MapReduce
- 能处理位于HDFS上的结构化数据
需求分析
SQL–>MapReduce
1
2
3
41、数据文件在哪
2、用什么符号作为列的分隔符
3、那些列可以作为city使用
4、city列是什么类型数据存储在关系型数据库里面(MySQL)
构建分布式MySQL
- 元数据管理功能:记录各类元数据信息
- 数据位置
- 数据结构
- 数据描述【字段名】
- 写一个SQL解析器(JAVA):完成SQL–>MapReduce的转换
- 分析SQL
- SQL–>MapReduce
- 提交MapReduce运行,并搜集结果
- 元数据管理功能:记录各类元数据信息
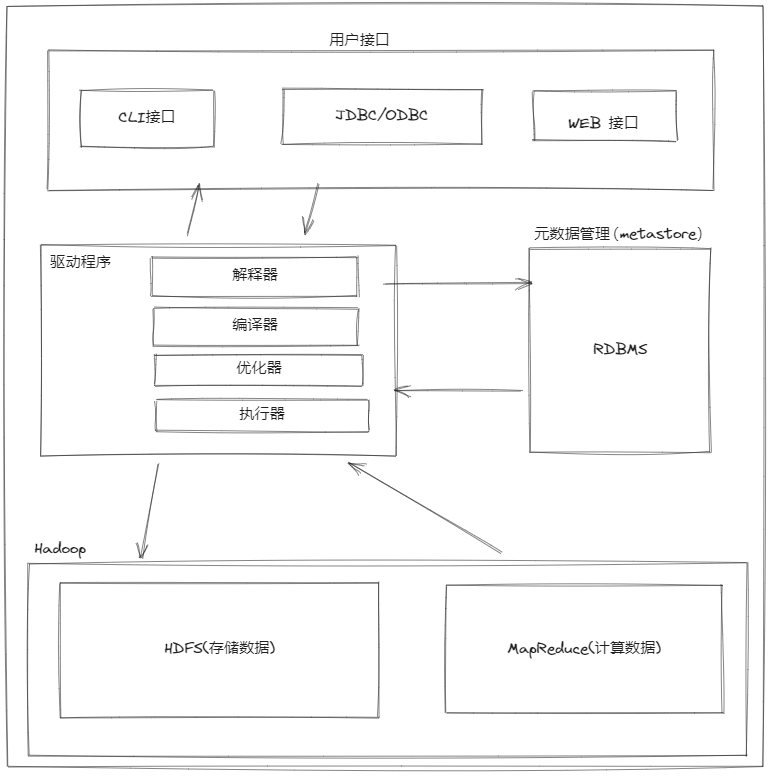
流程图

基本架构
用户接口
元数据存储
客户端连接MetaStore
metastore连接MySQL
MetaStore服务连接方式
本地模式
- 优点:可以单独使用外部数据库(MySQL),元数据共享
- 缺点:想对浪费支援,MetaStore嵌入到Hive,每启动一次Hive,都内置启动了
内嵌模式
- 优点:解压Hive安装包到hive/bin,可以直接连接
- 缺点:
远程模式(推荐)
- 优点:可以单独使用外部数据库(MySQL),元数据共享;可以连接MetaStore服务,也可以连接hiveserver2服务
- 缺点:==如果要启动hiveserver2服务,需要先启动MetaStore服务==
内嵌模式 本地模式 远程模式 单独配置、启动 否 否 是 存储介质 derby mysql mysql
启动MetaStore服务
- cd /export/server/hive/bin
- [nohup] ./hive –server metastore & :不挂起用hive在后台启动MetaStore服务
- [nohup] ./hive –server hiveserver2 &
lsof -i:10000 查看该端口有哪些进程在运行
Beeline
1. 启动beeline,/export/server/hive/bin/beeline 2. ! connect jdbc:hive2://node1:1000- crtl+d 退出
配置环境变量,快速启动hive
1
2
3
4sudo vim /etc/profile
echo '#HIVE_HOME'
echo 'export HIVE_HOME=/export/server/apache-hive-3.1.2-bin' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin' >> /etc/profile
数据仓库和数据库
1
2
3
4
5
61. 数据库(OLTP):用于把数据结果给外部各类程序使用,侧重于CRUD
2. 数据仓库(OLAP):
1. 面向主题
2. 集成的
3. 非易失的(不可更新)
4. 时变的ETL和ELT(将数据加载到数仓中)
- ETL:先从数据源池中,抽取数据,保存在临时数据仓库中(ODS)
- Extract 抽取
- Transform 转化
- Load 装载
- 工具:kettle
- ELT:数据在数据源中抽取后立即加载,没有临时数据库(ODS),数据会立即加载到单一的集中存储库中
- ETL:先从数据源池中,抽取数据,保存在临时数据仓库中(ODS)
Hive数据库操作
HQL
DDL:数据定义语言/数据描述语言
数据对象:数据库、数据表、视图、索引
核心语法:
1. 创建:create- 删除:drop
- 修改:alter
- 不涉及表内操作
创建数据库(可以用schema表示数据库)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 全英文,不要有中文
# 创建数据库
create database [if not exists] 数据库名 [设置编码格式];
[comment '解释说明'] #注释说明语句
[location '存储到HDFS路径名'] # 默认路径 hdfs://node1:8020/user/hive/warehouse
[with dbproperties (属性='值', ...)] # 数据库的属性配置,键值对
-- 1 在默认路径新建一个班级db1、db2, 给其中一个库添加一些注释
CREATE DATABASE db1;
create database db2 comment "database db2 for sz40";
-- 2 新建一个添加了属性信息的班级——DB4
create database db3 with dbproperties ("cls_name"="sz_pyb_40");
-- 3 新建DB3,并指定存储路径为:/itheima
create database db4 location "/ithaima";查看数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15desc database extended 数据库名;
1)extended用于显示更多信息,比如位置路径等;
-- 查看所有数据库
show databases;
-- 查看创建数据库语句
show create database 数据库名;
-- 切换数据库
use 数据库名;
-- 查看当前正在使用的数据库
select current_database();删除数据库
1
2
3drop database 数据库名 [restrict | cascade];
-- restrict是默认行为,表示限制,即仅在数据库为空时才删除它;
-- cascade 数据库中带表时,需要加修改数据库
1
2
3
4-- 修改数据库存储路径
alter database 数据库名 set locatio 存储路径;(绝对路径)
-- 修改或新增数据库配置
alter database 数据库名 set dbproperties (属性名=值, ...)