Hadoop基础(一)
Hadoop基础(一)
你我皆温柔Hadoop基础
什么是大数据?
- 为了处理海量数据所产生的技术
- 通过分布式技术处理数据
应用
- 数据挖掘
分布式
将多台服务器集中,每台服务器做不同的事情
分布式系统:一个硬件或软件,其组件会分布在不同的计算机上,并可以通过网络进行通信和协调
常用技术
分布式数据存储:HDFS

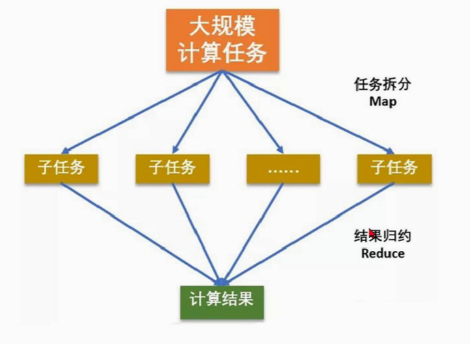
分布式计算:MapReduce
集群
多台不同服务器部署相同的应用或服务模块
负载均衡,提供服务
资源调度:YARN
- 去中心化模式:没有主服务器,基于特定规则同步协调
中心化模式:有一个主服务器,都由主服务器统一调度分配
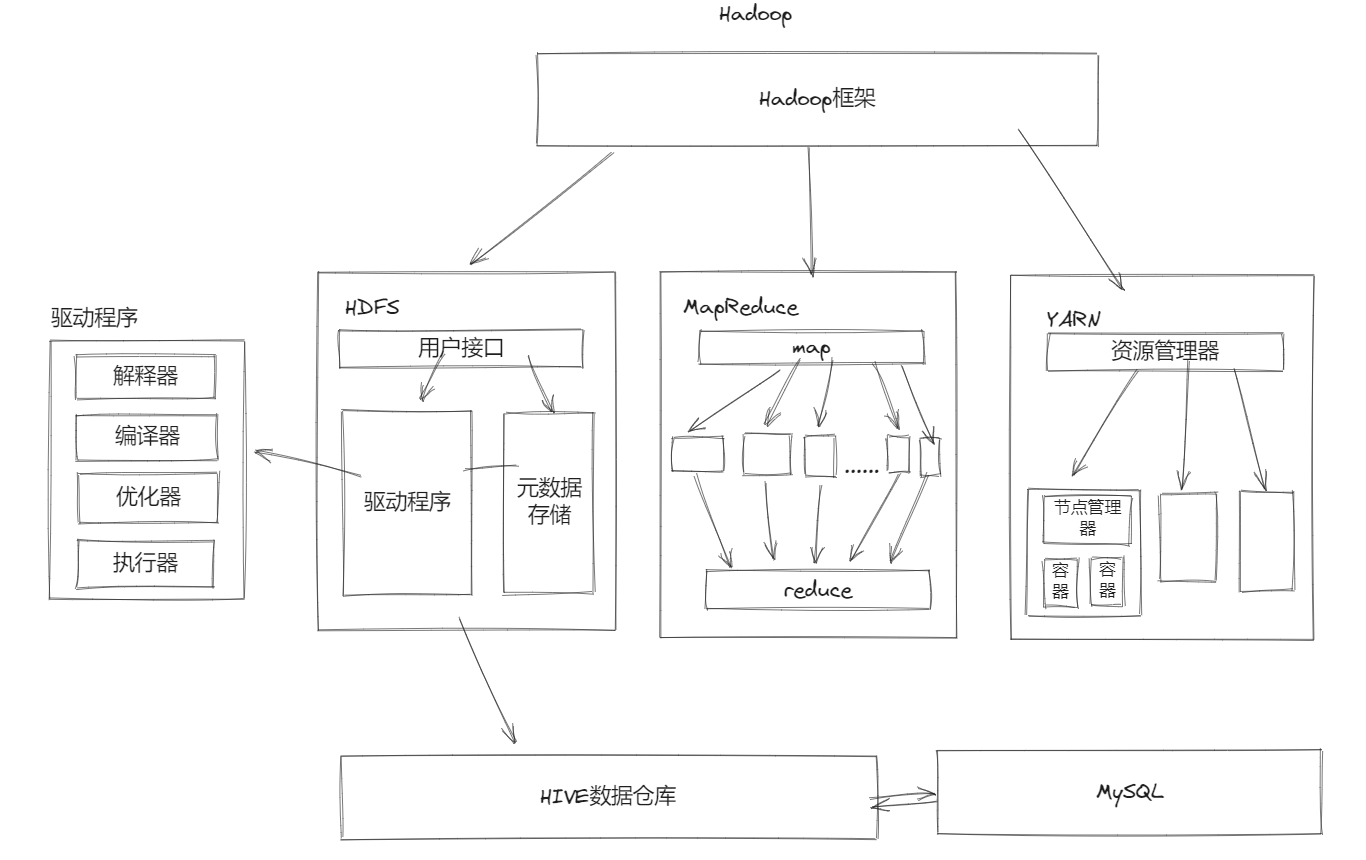
Hadoop框架
- 核心工作
- 数据存储
1. HDFS:分布式存储
2. HBase:NoSQL(key-value)
3. Kudu
4. 云平台存储- 数据计算
- MapReduce
- Hive
- Spark
- Flink
- 数据传输
- Sqoop(ETL工具)
- Flume(流式数据采集)
- Kafka(分布式消息系统)
- Pulsar(分布式消息系统)
- 数据计算
入门
Hadoop优势
扩容能力
- 成本低
- 效率高
- 可靠性
HDFS
- NameNode:主节点
- secondaryNameNode:辅助主节点,备份元数据
- DataNode:存储集群中的数据
YARN
- ResourceManager:接收用户计算请求任务,负责集群资源分配
NodeManager:执行主节点分配任务
MapReduce(分而治之)
Hadoop启动
HDFS上使用shell命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24法一
hadoop fs -<args> #既可以操作HDFS,也可以操作本机系统
# 法二
hdfs dfs -<args> #只能操作HDFS系统
# 实例
hdfs dfs 回车 查看所有命令
hdfs dfs -help 帮助
hdfs dfs -ls 显示文件列表
-R # 递归显示文件列表
hdfs dfs -mkdir 创建目录
-mkdir -p 创建多级目录
hdfs dfs -mv 重命名文件或目录或移动文件或目录
hdfs dfs -touch /a/a.txt 创建a.txt文件
hdfs dfs -cp 复制文件或目录
hdfs dfs -rm 删除文件或目录
hdfs dfs -cat 查看文件内容
hdfs dfs -put 上传本地文件或目录到hdfs上
hdfs dfs -get 下载hdfs上的文件或目录到本地
hdfs dfs -appendToFile /path/to/local/h.txt /user/hadoop/itcast/a.txt 将本地文件中的内容追加到HDFS上的文件里面
# 启动例子统计词频
cd /export/server/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /outputHadoop目录结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19tree查看一级目录
tree -L 1
hadoop
├── bin # Hadoop最基本的管理脚本和使用脚本所在的目录
├── etc # 存放一些hadoop的配置文件
├── include # 编程库头文件,用于C++程序访问HDFS或者编写MapReduce程序
├── lib # 存放的是Hadoop运行时依赖的jar包,Hadoop在执行时会把lib目录下面的jar全部加到classpath中
├── libexec # 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息
├── LICENSE-binary
├── licenses-binary
├── LICENSE.txt
├── logs # Hadoop运行的日志
├── NOTICE-binary
├── NOTICE.txt
├── README.txt
├── sbin # 管理脚本的所在目录,重要是对hdfs和yarn的各种开启和关闭和单线程开启和守护
└── share # 各个模块编译后的jar包所在的目录
Hadoop框架