SQL优化
SQL优化
你我皆温柔SQL优化
(1)SQL语句有哪些优化手段?能具体说明一下吗?
- select 只查需要的字段,尽量避免使用count(*)、select * 之类的作为要查询的内容
- 多表关联查询,应使用内连接或外连接;关联的表太多时,先把需要的字段查出来组成一个虚拟表,在虚拟表的基础上进行关联查询
- 通过索引查询
- B+树:非叶子节点只存索引值,不存数据;数据在叶子节点存的,在底层叶子节点之间是以双向链表的形式连接(在范围查询时可以之间查询,避免回表,提升查询效率)
- 基于以上数据结构的特性,通过索引查询相比较全表扫描会极大的提高查询效率
- 避免使用is null\is not null\in\or\like模糊查询作为查询条件,因为这些条件可能会导致索引失效,从而进行全表扫描
- like模糊查询:避免使用”%xx”,无法命中索引导致索引失效,而进行全表扫描
- in:当数据量比较少的时候会尝试走索引,数据量超过一定的临界值时,就不走索引了
- is null 或者 is not null :对单列索引,会尝试走索引
- 会不会走索引,要看数据库的优化器,当优化器认为全表扫描要比走索引快的时候,将会进行全表扫描
- 嵌套查询的时候:子查询结果集越大用EXISTS,子查询结果集越小,使用IN的索引优化效果更佳
- IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
- 外表比较大的话,in可能不会走索引,而是进行全表扫描,所以此时用exists比in效果好
- 建议:在使用前可以先用 explain 来试试到底sql语句走不走索引,然后选择较优的sql。
(2)有一个数据表t,拥有字段id,name员工名称,dept员工部门,salary工资,请使用SQL求解出每个部门薪资最高的前3名,并说清楚原理。
1 | select name , dept, salary |
扩展
索引的种类

常见的索引数据结构
每个树节点都是一次IO,树的高度影响数据查询的性能
二叉树:有序数据插入会导致不平衡,树的高度会变高,极限情况下会形成一个链表
- 数据结构(MySQL不支持):插入数据时,大在右,小在左
红黑树(平衡二叉树):通过自旋平衡,避免顺序插入,导致树过高
- 数据结构:达到一定数量,会将中间节点提升一级
- 有序插入时,就不会形成一个列表
- 数据量太大时,树的高度还是会很高
B树(平衡多路查找树): 相比于红黑树,B树的一个父结点,允许多个子结点(>2)
- 有阶的概念, 3阶B树则有3个分支
- 父节点允许存储多个数据,3阶B树,一个结点多与3个元素时,会将中间的元素提升一级,作为父节点
- MySQL是16阶的B+树
- 范围查询不太友好
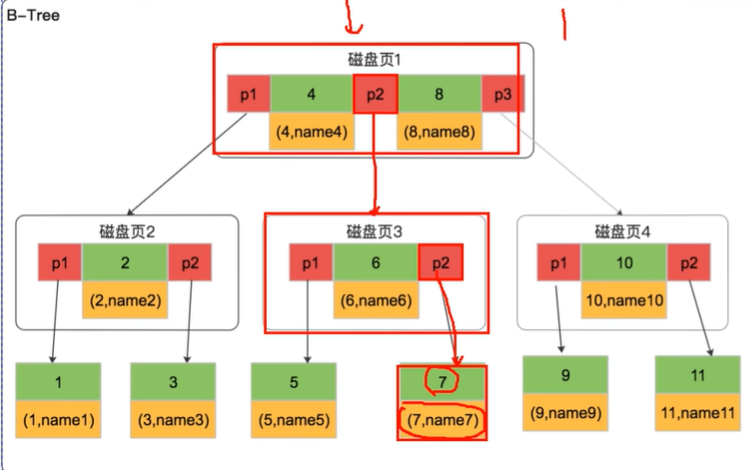
B+树:在B树的基础上,非叶子结点不存数据,只存索引,数据都存储在叶子结点

- 非叶子结点存储寻址结点
- 叶子结点之间通过链表连接 (两个结点之间添加双向指针)
- 范围查询友好
B树和B+树的区别
- 非叶子结点可以存储更多的索引键值,阶数就会更大,查询数据时IO大大减少,数据查询效率更快
- 数据都存在叶子结点,使范围、排序、分组查找更加简单快速
- 数据页、数据记录之间通过链表连接,方便在数据查询后升序或降序操作
Hash索引:InnoDB只支持自适应Hash索引
- 会产生哈希冲突
- 拉链法
- 再寻址法
- Hash索引只能用于等值查询,不支持范围、不支持排序
聚集索引和非聚集索引

- 聚集索引:数据和索引存在一起
- 非聚集索引:数据和索引不存在一起
单列索引:
联合索引:多个字段
- 尽量符合最左前缀原则,最左边尽量放有序的
- where 索引,其他字段
- 优势
- 减少开销:建立一个联合索引,多个索引组成一个
- 覆盖索引:直接通过遍历索引获取到数据
- 查询效率高
- 缺点:
- 创建和维护索引需要消耗时间
- 索引占用空间
- 降低表的增删改效率,每次改索引,都要动态维护
- 频繁作为查询条件的创建索引
- 字段唯一性太差不适合单独做索引
- 更新频繁的字段不适合
- 不会出现在where中的字段不适合做索引
覆盖索引:
- 会减少回表次数
二级索引:非聚集索引,所有非主键索引
- 先查询到叶子结点,存主键ID; 回表到主键索引,再查对应数据
索引下推:范围查询、二级索引
- 查询到所有相关字段后,一次性回表
explain
expain SQL语句
查看执行性能
索引优化
- 全值匹配:age=’18’
- 最左前缀原则:where 最左边一定要是索引
- 索引列上不进行计算
- 范围查询后面全失效:故范围查询条件尽量写到最后面
- 覆盖索引不要写*
- !=、null、or索引失效要少用
- force index() 强制使用索引
- like的%尽量写到右边
- 利用B+树的有序性
- 差距
- 知道部分内容,查匹配字段
- 先全表扫描再匹配字段
- var的引号不能丢
- 字符串类型不能丢掉引号,会不走索引
- 范围查询优化
- 优化器评估全表扫描和索引,计算出来的评分进行评判,判断是全表扫描还是走索引
SQL优化:
避免写select * 、count(*)
- 增加查询解析器的成本
- 不走索引覆盖,产生大量回表
- 不查无用字段
用小表驱动大表
- 30条数据 80万数据
- from 小表 join 大表
- 先遍历小表,再匹配大表
连接查询代替子查询
- from 小表 join 大表
提升group by 的效率
- 先排序后分组
- 为group by 字段添加索引
批量插入
- 避免多次请求mysql
- 500以内;避免内存溢出、死锁
使用limit进行分页
- 数据量过大,要分页
- offset 偏大后limit会变慢
- 利用主键索引
- 在子查询中只查ID,外表只查需要的数据
- 用join 替代 in
union all 代替 union
- 多表关联尽量使用union all
- 必须使用union时,使用索引
尽量少关联表
- join 不易过多
- 维护难度大(分库分表时,维护不易)

演讲顺序
- 底层数据结构:B+树
- 可以自旋,使树尽量保持平衡(当一个父结点的元素达到一定数量时,会将中间的元素提升一级作为父结点)
- 一个父结点可以有多个子结点,MySQL是一个16阶的B+树
- 叶子结点之间有双向指针进行链接,对于范围查询比较友好
- 基于上述特点,B+树的高度大大降低
- 从SQL语句的结构上来说
- select这一行:尽量避免使用select *,count( * );尽量只查询自己需要的字段,减少多余的字段
- from这一行:
- 尽量表连接代替子查询;
- 用小表驱动大表,将数据量小的表作为主表
- 尽量少关联表(如果关联表过多的话,可以先把需要的字段查出来构成成虚拟表,然后再进行关联查询),在后期进行分库分表之后,要对这些关联表的SQL进行维护,比较麻烦)
- where这一行:
- 避免使用范围查询,如果实在要用到范围查询,尽量写在查询条件的最后面,因为范围查询常常会导致索引失效(像is null、is not null、>、<、!=、or等);
- 当用到索引时,最好是全值匹配(每个字段都用索引);否则尽量符合最左前缀原则(在联合索引中,总是从最左边开始匹配,如a,b,c)
- 如果用到了模糊查询,一定要用后模糊(xx%)
- 字符串类型的字段,查询的时候引号不能丢,会导致不走索引
- 嵌套查询的时候:子查询结果集越大用EXISTS,子查询结果集越小,使用IN的索引优化效果更佳
- IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
- 外表比较大的话,in可能不会走索引,而是进行全表扫描,所以此时用exists比in效果好
- 当数据量比较少的时候会尝试走索引,数据量超过一定的临界值(优化器会先计算出一个值,数据量的30%)时,就不走索引了
- group by:分组字段尽量有索引的字段
- order by:排序字段能走索引最好
- limit:可以使用分页查询来优化查询性能,尤其是数据量较大的时候
- 会不会走索引,要看数据库的优化器,当优化器认为全表扫描要比走索引快的时候,将会进行全表扫描
- 索引列上尽量不要进行计算
- 建议:在使用前可以先用 explain 来试试到底sql语句走不走索引,然后选择较优的sql。

喜欢这篇文章的人也看了


